
Modular ISAs for Programmable Accelerators
Why do accelerators need ISAs?
Programmable accelerators enable architects to balance the classic tradeoff between architecture generality and efficiency. The basic approach in such designs is to codesign the microarchitecture with application kernels to specialize for certain program properties. Then, such an approach exposes certain lower-level aspects of their execution through a rich hardware/software interface. It is the existence of a hardware/software interface (ie. the accelerator-ISA) that enables us to rethink domain-specific architecture design not as a from-scratch enterprise with each new domain, but rather as an iterative exercise in creating richer more powerful hardware/software interfaces that can be reused in many problems.
An ideal “accelerator-ISA” would first be abstract enough, requiring a careful balance between the need to expose the lower level concurrency and communication features1 of the hardware with the desire to have a general purpose programmable interface. Second, it should be general, and be useful for parallelizable algorithms across a spectrum of regular and irregular problems. Finally, the accelerator-ISA should be modular, in the sense that certain features which perhaps require significant hardware cost to support should be removable from the ISA, should the become unnecessary in a domain. In this view, an accelerator-ISA is not the complete interface between hardware and software. The true interface comes from the description of the architecture, an ISA definition.
Do we have a good accelerator-ISA already? One proposal is vector ISAs, such as those used in a SIMD unit on a general purpose core, or the equivalent on a general purpose GPU. For simple data-parallel programs, vector-ISAs miss out on opportunities to specialize the communication between nearby instructions through programmable datapaths, instead relying on expensive centralized register files. For irregular programs, the problem is much worse; the vector abstraction leads to significant inefficient irregular (ie. data-dependent) memory access and control flow.
Our Accelerator ISA: Stream-Dataflow
We believe that an effective accelerator ISA decouples memory access and computation, and allows them to be specialized for in hardware separately. Stream-dataflow is our proposed ISA, which is the foundation of many of the ISAs that we have created. In this model, memory is expressed as ordered sequences of memory addresses in a given pattern – we refer to these as streams. Computation is expressed as a dataflow graph using streams as inputs and outputs.
The following is a simple example of a dot product. In dataflow form the streams are separated and expressed in a decoupled way from the computation of the loop. Its the ordering of the streams’ data which guarantees correct computation.
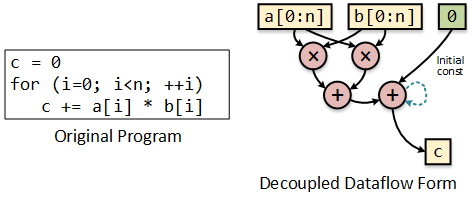
Our approach to enable flexibility is to embed the instantiation of streams and dataflow graphs into a VonNeumann program. More specifically, the dataflow graphs for computation are specified with a configuration instruction, while the streams are generated individually with instructions that setup stream parameters 2.
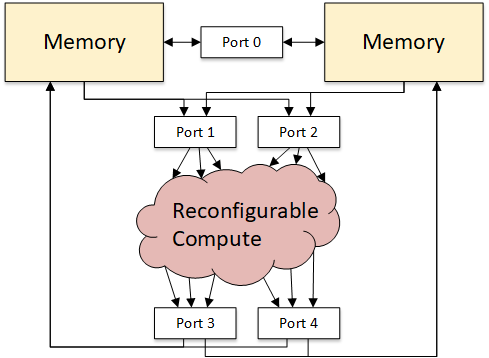
We also need some way for the streams to communicate with the computation graph – this is the job of ports. Ports as the named connection points between memories (the things that execute streams), and the computation graph. They are somewhat like registers, but with FIFO-like semantics.
The following shows the abstract view of an accelerator with two memories, and some ports to connect various components.
Streams have three basic components as shown below: a source, address pattern, and destination; the source and destination are either a port or memory. Different instances of stream-dataflow have supported different patterns, including affine (a[i]), indirect (a[b[i]]), and pointer chasing. Address patterns can even be interspersed with computation, making supported patterns extremely general.
Footnotes:
1 Ideally an Accelerator ISA would be able to expose expose all five “C’s” of specialization to the software: explicitly exposing concurrency, coordination of the program, communication between memory and operations, computation, and opportunity for caching (data reuse).
2 This isn’t quite an arbitrary decision, as there is an advantage to specifying computation independently. Often times some aspect of a stream will change, but the underlying computation graph doesn’t change. By decoupling, a change in eg. the start address of a stream doesn’t necessitate restating the dataflow graph.